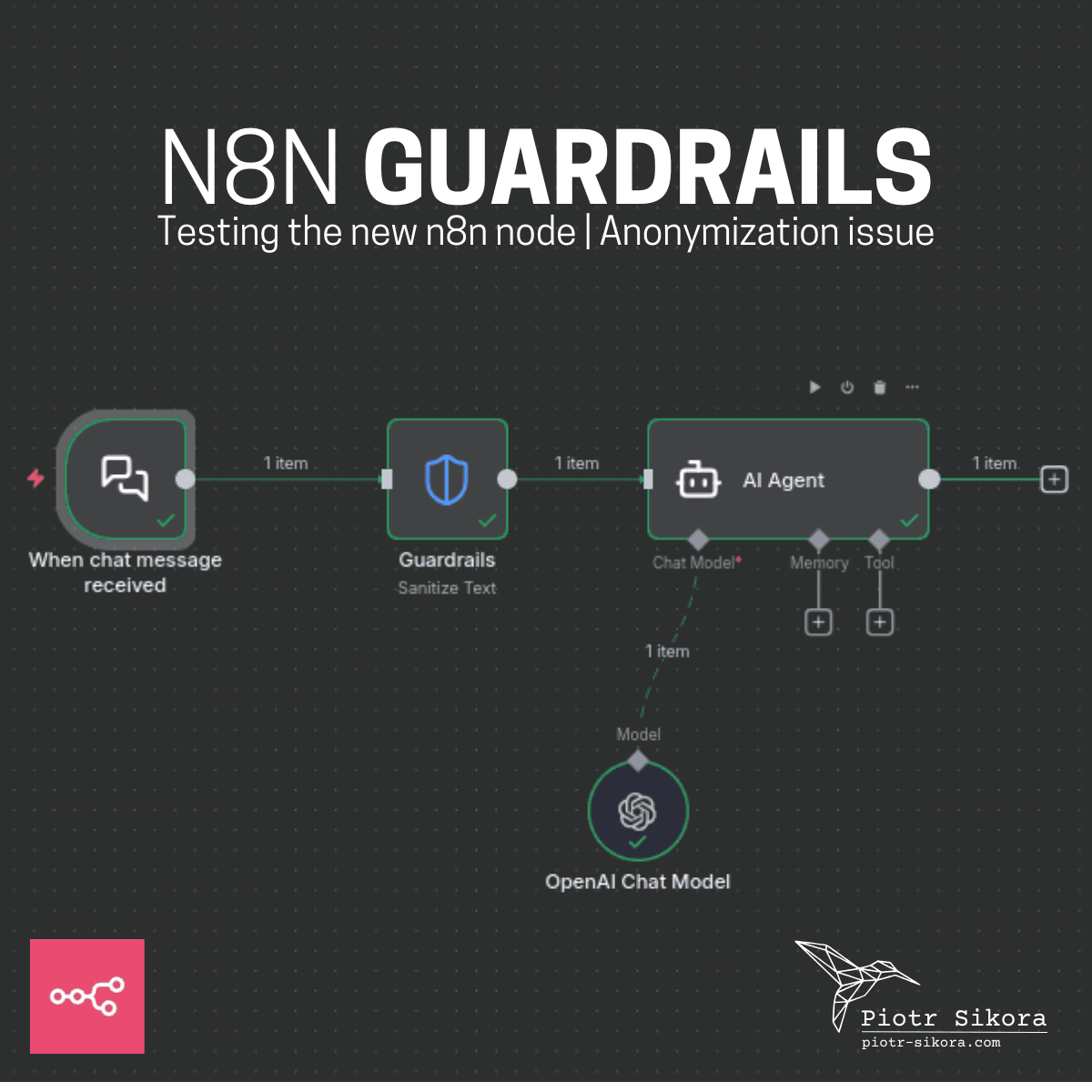
Rozpocząłem testy nowej funkcji Guardrails w n8n.
Kiedy węzeł Guardrails został ogłoszony 30 października 2025 roku podczas "n8n Livestream: AI Guardrails, Pinecone & Community Highlights", byłem szczerze podekscytowany. To dokładnie taka funkcja, na którą czekało wielu twórców automatyzacji AI.
Przeprowadziłem kilka testów - i tak, działa to naprawdę dobrze. Ale... jest jeden obszar, w którym mogłoby być znacznie lepiej.
Oto wyzwanie:
Załóżmy, że pracujesz ze zanonimizowanymi danymi i chcesz je bezpiecznie przekazać do Agenta AI.
Przykład:
"Będę pracować z dwoma emailami: adam@adam.com i kate@kate.com"
Po przepuszczeniu tego przez węzeł n8n Guardrails, otrzymujesz:
"Będę pracować z dwoma emailami <EMAIL_ADDRESS> i <EMAIL_ADDRESS>"
Idealnie. Dla standardowej anonimizacji — to dokładnie to, czego chcesz.
Ale co, jeśli musisz później przywrócić dane?
Wyobraź sobie, że generujesz projekt umowy
"Wykonawca identyfikuje się adresem email adam@adam.com, a klient adresem kate@kate.com"
Emaile powtarzają się wielokrotnie w całej umowie. Anonimizujesz -> przetwarzasz przez AI -> a następnie chcesz je zmapować z powrotem.
W idealnym scenariuszu otrzymałbyś coś takiego:
- <EMAIL_ADDRESS_1> - adam@adam.com
- <EMAIL_ADDRESS_2> - kate@kate.com
Dzięki temu mógłbyś bezpiecznie przywrócić oryginalną treść po analizie AI.
Ale przy obecnej implementacji Guardrails?
Każdy email staje się tym samym tokenem: <EMAIL_ADDRESS>
- Brak indeksu.
- Brak unikalnego ID.
- Brak powiązania.
Oznacza to: nie możesz niczego przywrócić.
I ta sama historia dotyczy:
- numerów kont bankowych
- numerów telefonów
W zasadzie każdych danych, które chcesz zanonimizować, a następnie przywrócić.
Czy ktoś z Was próbował rozwiązać to w n8n?
- Może używając węzła preprocessingu?
- Lokalnego modelu AI?
- Własnego replacera?
- Regex + tabela wyszukiwania?
- Lub zewnętrznej anonimizacji przed Guardrails?
Ciekaw jestem, czy ktoś już eksperymentował z tym wzorcem?







![Skuteczna anonimizacja danych wrażliwych — Guardrails w Bielik vs n8n [E010]](/_next/image?url=%2Fassets%2Fblog-images%2Fyt-videos%2FVzGEzDi8fAs.jpg&w=828&q=75)


Komentarze